Consider the following statements: ...Read more
Poll Results
Please login to vote and see the results.
Sign up to our innovative Q&A platform to pose your queries, share your wisdom, and engage with a community of inquisitive minds.
Log in to our dynamic platform to ask insightful questions, provide valuable answers, and connect with a vibrant community of curious minds.
Forgot your password? No worries, we're here to help! Simply enter your email address, and we'll send you a link. Click the link, and you'll receive another email with a temporary password. Use that password to log in and set up your new one!
Please briefly explain why you feel this question should be reported.
Please briefly explain why you feel this answer should be reported.
Please briefly explain why you feel this user should be reported.
At Qukut, our mission is to bridge the gap between knowledge seekers and knowledge sharers. We strive to unite diverse perspectives, fostering understanding and empowering everyone to contribute their expertise. Join us in building a community where knowledge flows freely and growth is limitless.
Consider the following statements: ...Read more
Please login to vote and see the results.
Given the current observational tension between the predicted large-scale cosmic structure derived from Cold Dark Matter (CDM) simulations and the observed distribution of galaxies, what implications do these discrepancies have for the nature of dark matter, and how do the ...Read more
The observational tension between the large-scale cosmic structure predicted by Cold Dark Matter (CDM) simulations and the actual observed distribution of galaxies has significant implications for the nature of dark matter. The discrepancies observed at small scales—such as the mismatch between theRead more
The observational tension between the large-scale cosmic structure predicted by Cold Dark Matter (CDM) simulations and the actual observed distribution of galaxies has significant implications for the nature of dark matter. The discrepancies observed at small scales—such as the mismatch between the predicted and observed number of satellite galaxies, as well as the core-cusp problem—have prompted reconsideration of the standard CDM paradigm and the exploration of alternative dark matter models. The findings from Lyman-alpha forest data and galaxy surveys are critical in constraining various dark matter candidates like sterile neutrinos and axions. The interplay between dark matter properties and the early universe dynamics could help resolve some of the observed anomalies, offering a path beyond the standard CDM model.
The early universe dynamics play a crucial role in shaping the behavior of dark matter, especially in terms of its influence on structure formation. The thermal history of the universe, which includes the decoupling of dark matter from the photon-baryon fluid, sets the initial conditions for how dark matter clusters and interacts in the post-recombination era. The interplay between dark matter properties and these early dynamics could help resolve some anomalies that arise within the CDM paradigm.
The discrepancies between the large-scale cosmic structure predicted by CDM and the observed distribution of galaxies challenge our understanding of dark matter and its properties. Observations from the Lyman-alpha forest and galaxy surveys are critical in constraining various dark matter candidates, such as sterile neutrinos and axions, and they provide strong evidence for the behavior of dark matter on small scales.
The interplay between dark matter properties and early universe dynamics offers a promising path to resolving these anomalies. By extending beyond the standard CDM paradigm, models like self-interacting dark matter (SIDM), sterile neutrinos, and axions provide different frameworks for understanding the formation of cosmic structures. Future observations, especially from EUCLID and other large surveys, will likely provide the key insights needed to refine or revise our models of dark matter and its role in the evolution of the universe.
See lessWhat are some lesser-known travel destinations in Europe?
what does the book why bharat matters signify ?
"Why Bharat Matters" by S. Jaishankar is a profound exploration of India's position in the global political arena, seen through the lens of its rich civilizational history. Jaishankar, India’s External Affairs Minister, delves into India’s foreign policy, utilizing historical, cultural, and philosopRead more
“Why Bharat Matters” by S. Jaishankar is a profound exploration of India’s position in the global political arena, seen through the lens of its rich civilizational history. Jaishankar, India’s External Affairs Minister, delves into India’s foreign policy, utilizing historical, cultural, and philosophical insights to illustrate the nation’s evolving role in world affairs.
A key feature of the book is its integration of India’s ancient epics, particularly the Ramayana and Mahabharata, to shed light on contemporary geopolitical challenges. By drawing comparisons between mythological figures like Hanuman and Sri Krishna and modern leadership, Jaishankar provides valuable perspectives on resilience, strategic thinking, and diplomacy
The book emphasizes India’s deep-rooted cultural values and its long history of engagement with the world. Jaishankar illustrates India’s humanitarian contributions, from disaster relief efforts to global health support, positioning India as a compassionate and reliable global partner
Jaishankar’s writing is accessible yet intellectually rich, offering readers a comprehensive view of India’s global aspirations while encouraging them to embrace the country’s civilizational virtues as a guiding force for international diplomacy
“Why Bharat Matters” is highly recommended for anyone interested in understanding India’s foreign policy, its cultural heritage, and its significant role in shaping the global order. It’s an insightful read for policymakers, scholars, and general readers alike. For more information, you can find the full review and more details on the book’s insights on various platforms like ReadByCritics.
Could intelligent life evolve differently due to different planetary conditions?
Yes, the evolution of intelligent life could vary significantly due to different planetary conditions. Planetary characteristics such as atmosphere, gravity, temperature, radiation, and available resources shape the development of life. Here's how different conditions might influence the evolution oRead more
Yes, the evolution of intelligent life could vary significantly due to different planetary conditions. Planetary characteristics such as atmosphere, gravity, temperature, radiation, and available resources shape the development of life. Here’s how different conditions might influence the evolution of intelligent beings:
These variations suggest that intelligent life could take many forms, adapting to their unique worlds in ways that may be vastly different from life as we know it. This diversity would reflect the incredible adaptability of life to thrive under varied conditions.
See lessTwo cars are on the same highway, 100 kilometers apart, heading toward each other at a speed of 50 km/h each. A bird starts at the front of one car and flies towards the other car at a speed of ...Read more
The Red Fort is located in which city?
Please login to vote and see the results.
Find the missing term in the series 3, 9, 27, 81, ?, 729
243 3×3=9 9×3=27 27×3=81 81×3=243 243×3=729
To differentiate the function \( h(x) = \frac{4x^3 - 7x + 8}{x} \) ,here's the step-by-step process: Given: \[ h(x) = \frac{4x^3 - 7x + 8}{x} \] Step 1: Simplify the function First, simplify the function by dividing each term in the numerator by \( x \): \[ h(x) = \frac{4x^3}{x} - \frac{7x}{x} + \frRead more
To differentiate the function \( h(x) = \frac{4x^3 – 7x + 8}{x} \) ,here’s the step-by-step process:
Given:
\[
h(x) = \frac{4x^3 – 7x + 8}{x}
\]
Step 1: Simplify the function
First, simplify the function by dividing each term in the numerator by \( x \):
\[
h(x) = \frac{4x^3}{x} – \frac{7x}{x} + \frac{8}{x}
\]
This simplifies to:
\[
h(x) = 4x^2 – 7 + \frac{8}{x}
\]
Step 2: Differentiate each term
Now, differentiate \( h(x) \) with respect to \( x \):
1. Differentiate \( 4x^2 \):
\[
\frac{d}{dx}(4x^2) = 8x
\]
2. Differentiate \( -7 \)(a constant):
\[
\frac{d}{dx}(-7) = 0
\]
3. Differentiate \( \frac{8}{x} \):
Rewrite \( \frac{8}{x} \) as \( 8x^{-1} \).
\[
\frac{d}{dx}(8x^{-1}) = -8x^{-2}
\]
Step 3: Combine the derivatives
Finally, combine the derivatives:
\[
h'(x) = 8x + 0 – \frac{8}{x^2}
\]
Or, simply:
\[
h'(x) = 8x – \frac{8}{x^2}
\]
This is the derivative of the given function \( h(x) = \frac{4x^3 – 7x + 8}{x} \).
See less
Select any one of the following options given above.
Please login to vote and see the results.
The village known as "The Most Haunted Village of India" is Kuldhara, located near Jaisalmer in Rajasthan. Kuldhara is often referred to as a ghost village due to its abandoned state and the legends surrounding its desolation. According to local lore, the village was once home to the Paliwal BrahminRead more
The village known as “The Most Haunted Village of India” is Kuldhara, located near Jaisalmer in Rajasthan. Kuldhara is often referred to as a ghost village due to its abandoned state and the legends surrounding its desolation. According to local lore, the village was once home to the Paliwal Brahmins, who fled overnight in 1825 to escape the oppressive demands of a local minister, leaving behind a curse that no one would ever be able to inhabit the village again.
While Kuldhara is recognized for its haunted reputation, it’s worth noting that Bhangarh Fort is frequently cited as the most haunted place in India, although it was not included in your options. The stories and eerie atmosphere surrounding both locations attract many visitors interested in the supernatural.
See lessHow is the celebration of Corpus Christi and Transubstantiation related to the development of English drama??
The celebration of Corpus Christi and the doctrine of Transubstantiation were deeply intertwined with the development of English drama, particularly in the Middle Ages. Here's how they are connected: 1. Corpus Christi Feast and Liturgical Drama Corpus Christi is a feast celebrating the belief in theRead more
The celebration of Corpus Christi and the doctrine of Transubstantiation were deeply intertwined with the development of English drama, particularly in the Middle Ages. Here’s how they are connected:
The celebration of Corpus Christi and its focus on Transubstantiation provided the theological and cultural foundation for the mystery play cycles, which became a pivotal phase in the evolution of English drama. These plays not only taught religious doctrine but also laid the groundwork for theatrical traditions that evolved into the rich tapestry of English Renaissance drama.
See lessWhat is the true purpose of human existence?
The true purpose of human existence is a deeply philosophical question, and the answer can vary depending on one's beliefs, cultural perspectives, and individual experiences. Several schools of thought offer different perspectives on the matter: 1. Philosophical Perspectives Existentialism: ThinkersRead more
The true purpose of human existence is a deeply philosophical question, and the answer can vary depending on one’s beliefs, cultural perspectives, and individual experiences. Several schools of thought offer different perspectives on the matter:
1. Philosophical Perspectives
Existentialism: Thinkers like Jean-Paul Sartre and Albert Camus suggest that life inherently lacks a predefined purpose. Instead, individuals must create their own meaning through choices, actions, and personal freedom.
Absurdism: Albert Camus also introduced the concept of absurdism, arguing that humans naturally seek meaning in a chaotic, indifferent universe. While the search for meaning may seem futile, embracing the absurdity and continuing to live fully is a form of personal liberation.
Humanism: From a humanist perspective, the purpose of life may be to seek fulfillment through personal growth, the improvement of society, and the pursuit of knowledge and happiness.
2. Religious Perspectives
Christianity: In Christian doctrine, the purpose of human life is often seen as fulfilling God’s will, following the teachings of Jesus Christ, and striving for salvation through faith, love, and compassion.
Hinduism: Hindu philosophy suggests that life’s purpose is to attain moksha (liberation from the cycle of birth, death, and rebirth) through righteous living, self-discipline, meditation, and devotion to God.
Buddhism: In Buddhism, the purpose is to achieve nirvana (enlightenment), which involves overcoming suffering and the cycle of rebirth by following the Eightfold Path, emphasizing ethical conduct, meditation, and wisdom.
Islam: In Islam, human existence is believed to be a test from God (Allah), where the purpose is to worship Him, lead a moral life, and prepare for an eternal life in the afterlife.
3. Scientific and Evolutionary Perspectives
Biological Evolution: From an evolutionary standpoint, the “purpose” of human existence could be seen as the continuation of the species through reproduction and the passing on of genetic material. However, many scientists also acknowledge that humans have the capacity for self-awareness, morality, and creating purpose beyond survival instincts.
Cosmology and the Universe: Some scientists approach the question from a cosmological angle, arguing that human existence is an outcome of the natural processes of the universe. In this context, humans are just one part of an immense, ever-evolving universe with no intrinsic purpose other than what individuals assign to their lives.
4. Personal Meaning and Fulfillment
Many people find purpose in personal experiences and relationships. The pursuit of happiness, fulfillment, and making meaningful contributions to the well-being of others are often seen as vital aspects of a person’s life purpose. This may involve creating art, raising a family, advancing knowledge, or helping others achieve their potential.
Conclusion
Ultimately, the true purpose of human existence is subjective and multifaceted. It may be a combination of the search for personal meaning, contributing to society, spiritual growth, or the pursuit of knowledge. While some may find purpose in religious faith, others in personal development, and still others in social impact, the beauty of this question lies in the fact that every individual has the ability to define their own path and purpose.
See lessThe theory of relativity, developed by Albert Einstein in the early 20th century, revolutionized our understanding of space, time, and gravity. It consists of two main parts: special relativity and general relativity. Special Relativity (1905) This theory deals with the physics of objects moving atRead more
The theory of relativity, developed by Albert Einstein in the early 20th century, revolutionized our understanding of space, time, and gravity. It consists of two main parts: special relativity and general relativity.
This theory deals with the physics of objects moving at constant speeds, particularly those approaching the speed of light. Its core concepts include:
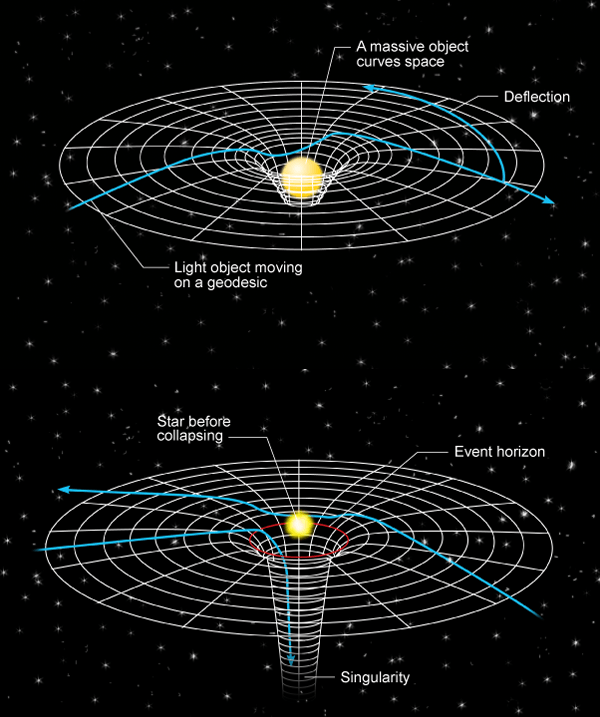
Source: Physics Magazine
Key consequences of special relativity:
This theory extends special relativity to include acceleration and introduces a new understanding of gravity. Its core ideas are:
Key consequences of general relativity:
Einstein’s theories have been confirmed through numerous experiments and observations, such as the bending of light by gravity and the precise timekeeping of GPS satellites, which must account for both special and general relativity effects. These theories form the foundation of modern physics, especially in understanding the cosmos, from black holes to the expansion of the universe.
See lessWhich one of the following activities of the Reserve Bank of India is considered to be part of ‘sterilization? ...Read more
Please login to vote and see the results.
Sterilization refers to actions taken by the central bank (in this case, the Reserve Bank of India) to manage the impact of foreign capital flows on the domestic money supply. Open Market Operations (OMOs) are one such tool where the central bank buys or sells government securities in the open markeRead more
Sterilization refers to actions taken by the central bank (in this case, the Reserve Bank of India) to manage the impact of foreign capital flows on the domestic money supply. Open Market Operations (OMOs) are one such tool where the central bank buys or sells government securities in the open market to influence liquidity and control inflation or currency appreciation/depreciation. This process helps in managing the domestic monetary base without affecting other macroeconomic variables. Therefore, the correct answer is Conducting ‘Open Market Operations’.
See lessWhat are the main components of the Earth’s atmosphere?
Nitrogen, oxygen, argon, and carbon dioxide are the main components.
Nitrogen, oxygen, argon, and carbon dioxide are the main components.
See lessHow do plants grow towards light (phototropism)?
Plants grow toward light through a process called phototropism, which is a directional growth response where plants orient themselves toward or away from a light source. This behavior is primarily controlled by plant hormones and cellular mechanisms. Steps of Phototropism Perception of Light: SpeciaRead more
Plants grow toward light through a process called phototropism, which is a directional growth response where plants orient themselves toward or away from a light source. This behavior is primarily controlled by plant hormones and cellular mechanisms.
Phototropism enables plants to optimize their growth for sunlight by detecting light direction, redistributing auxin, and bending shoots toward the light source. This adaptive mechanism is vital for a plant’s survival and efficient energy production.
See lessHow would you design a global education system that ensure equal access to quality education for student from all socieoeconomics backgrounds , considering differences in technology of availability,cultural values and teaching method? But inovative tools or strategies would you impliment ...Read more
To ensure equal access to quality education globally 🌍, I would create a hybrid learning system combining online platforms 📱💻 and community learning hubs 🏫. Solar-powered devices ☀️🔋 would provide internet to remote areas, while AI-driven personalized learning 🤖📚 adapts to students’ needs. CulturallRead more
To ensure equal access to quality education globally 🌍, I would create a hybrid learning system combining online platforms 📱💻 and community learning hubs 🏫. Solar-powered devices ☀️🔋 would provide internet to remote areas, while AI-driven personalized learning 🤖📚 adapts to students’ needs. Culturally sensitive curricula 🌐📖 would respect local values, and teachers would receive global-standard training 🎓👩🏫. Public-private partnerships 🤝 would fund the initiative, ensuring no child is left behind 🚸✨.
See lessA star chart is a celestial map of the night sky with astronomical objects laid out on a grid system. They are used to identify and locate constellations, stars, nebulae, galaxies, and planets. They have been used for human navigation since time immemorial.
A star chart is a celestial map of the night sky with astronomical objects laid out on a grid system. They are used to identify and locate constellations, stars, nebulae, galaxies, and planets. They have been used for human navigation since time immemorial.
See lessDr.BR ambedkar he was the one of the greatest man in India to introduced constitution.
Dr.BR ambedkar he was the one of the greatest man in India to introduced constitution.
See lessAre aliens more likely to be carbon-based like us or something entirely different?
Aliens are more likely to be carbon-based, like us, but the possibility of life forms based on entirely different chemistries cannot be ruled out. Here's why carbon is considered likely, along with the potential for alternatives: Carbon-Based Life Chemical Versatility: Carbon atoms can form stable bRead more
Aliens are more likely to be carbon-based, like us, but the possibility of life forms based on entirely different chemistries cannot be ruled out. Here’s why carbon is considered likely, along with the potential for alternatives:
While carbon-based life is the most likely due to its chemical advantages, the universe’s vastness means there could be forms of life with completely different biochemical foundations, especially in environments drastically different from Earth. Our search for life often focuses on carbon because it’s the most familiar and understood, but scientists remain open to discovering entirely novel life forms.
See lessWhat happens in the deep consciousness during a near-death experience?
Near-death experiences (NDEs) are profound events reported by individuals who have come close to death or experienced life-threatening situations. While scientific explanations and spiritual interpretations vary, here’s a breakdown of what is believed to happen in the deep consciousness during suchRead more
Near-death experiences (NDEs) are profound events reported by individuals who have come close to death or experienced life-threatening situations. While scientific explanations and spiritual interpretations vary, here’s a breakdown of what is believed to happen in the deep consciousness during such experiences:
In essence, near-death experiences remain a profound mystery, blending elements of neuroscience, psychology, and spirituality. They challenge our understanding of consciousness, offering insights into what might lie beyond ordinary perception.
See lessOperation Sagar Bandhu (translated as "Friend of the Seas") is a major humanitarian mission launched by India on November 28, 2025, to assist Sri Lanka in the aftermath of the devastating Cyclone Ditwah. The operation is a prime example of India's "Neighbourhood First" policy and its Vision MAHASAGARead more
Operation Sagar Bandhu (translated as “Friend of the Seas”) is a major humanitarian mission launched by India on November 28, 2025, to assist Sri Lanka in the aftermath of the devastating Cyclone Ditwah. The operation is a prime example of India’s “Neighbourhood First” policy and its Vision MAHASAGAR (Mutual and Holistic Advancement for Security and Growth Across Regions), positioning India as the primary “first responder” for natural disasters in the Indian Ocean.
Humanitarian Aid: India has delivered over 1,134 tonnes of essential supplies, including dry rations, fresh food, medicines, surgical equipment, tents, and water purification units.
Search and Rescue (SAR): Indian helicopters (Chetak and MI-17) have rescued hundreds of stranded individuals, including pregnant women, infants, and foreign nationals from over a dozen countries.
Infrastructure Restoration: An Engineer Task Force from the Indian Army was deployed with Bailey bridges and heavy machinery to restore critical road connectivity in flood-hit regions like Kilinochchi.
Medical Assistance: The Indian Army’s 60 Parachute Field Hospital treated more than 7,000 patients, providing surgical, dental, and general medical care in severely affected areas.
The mission saw a massive, coordinated effort between the Indian Navy, Air Force, and Army:
Indian Navy: Deployed the aircraft carrier INS Vikrant, the frigate INS Udaygiri, and several other ships including INS Sukanya and INS Gharial.
Indian Air Force: Utilized C-130J Super Hercules and C-17 Globemaster transport aircraft for rapid airlifting of personnel and heavy equipment.
Indian Coast Guard: The ship ICGS Shaurya delivered significant consignments of dry rations.
NDRF: Specialized teams from the National Disaster Response Force assisted in ground-level search and recovery operations.
Can anyone earn money at sitting home by using phone?
Yes, many people can earn money from home using just their phone. Here are some popular methods: Freelancing Platforms: Websites like Fiverr, Upwork, and Freelancer allow you to offer services such as writing, graphic design, programming, social media management, and more. How to Start: Create a proRead more
Yes, many people can earn money from home using just their phone. Here are some popular methods:
Each of these options requires different levels of skill, time commitment, and initial investment, but they can all be done from the comfort of your home using just your phone.
See lessCould humans survive on Mars without terraforming?
Humans cannot survive on Mars without significant life-support systems. The planet’s thin atmosphere (95% carbon dioxide), extreme cold, lack of liquid water, and harmful radiation make it inhospitable. Terraforming would be required for long-term, large-scale habitation.
Humans cannot survive on Mars without significant life-support systems. The planet’s thin atmosphere (95% carbon dioxide), extreme cold, lack of liquid water, and harmful radiation make it inhospitable. Terraforming would be required for long-term, large-scale habitation.
See less
Magnets work based on the principles of electromagnetism, which is governed by the behavior of electrons in atoms. Here’s a breakdown of how magnets function: 1. Atomic Structure and Magnetic Domains Every atom has electrons that orbit its nucleus. These electrons generate tiny magnetic fields as thRead more
Magnets work based on the principles of electromagnetism, which is governed by the behavior of electrons in atoms. Here’s a breakdown of how magnets function:
Magnets are fascinating examples of how atomic-scale forces manifest into something tangible and incredibly useful!
See lessWhat is the next number in the series: 10, 9, 11, 8, 12, 7, ___
Answer will be 13 as 7+6=13
Answer will be 13 as 7+6=13
See lessWhat are the different natural vegetations of South America?
South America, with its diverse climate zones and ecosystems, is home to a wide variety of natural vegetation types. These vegetation zones are influenced by factors such as latitude, altitude, rainfall, and temperature. The main natural vegetation types found across the continent include: 1. TropicRead more
South America, with its diverse climate zones and ecosystems, is home to a wide variety of natural vegetation types. These vegetation zones are influenced by factors such as latitude, altitude, rainfall, and temperature. The main natural vegetation types found across the continent include:
South America’s natural vegetation is incredibly diverse, reflecting the continent’s varied climates and geographic features. From the lush, biodiverse rainforests of the Amazon to the arid deserts of the Andes, the continent’s vegetation zones support an array of wildlife and are essential to the planet’s ecological balance. These ecosystems are also critical for human economies, providing resources for agriculture, timber, and tourism.
See lessLever is the force placed between the fulcrum and the load. If the load is closer to the fulcrum, researchers of movement in the load require less force. If the force is closer to the fulcrum, movement of the load requires more force.
Lever is the force placed between the fulcrum and the load. If the load is closer to the fulcrum, researchers of movement in the load require less force. If the force is closer to the fulcrum, movement of the load requires more force.
See less“Souls are not only the property of animal and plant life, but also of rocks, running water and many other natural objects not looked on as living by other religious sects.” ...Read more
Please login to vote and see the results.
The statement reflects one of the core beliefs of Jainism. Jainism emphasizes the idea that all living beings, including plants, animals, and even non-living entities like rocks and water, possess souls (jiva) and that all life is interconnected. This belief in the sanctity of all forms of life is fRead more
The statement reflects one of the core beliefs of Jainism.
Jainism emphasizes the idea that all living beings, including plants, animals, and even non-living entities like rocks and water, possess souls (jiva) and that all life is interconnected. This belief in the sanctity of all forms of life is fundamental to Jain philosophy and ethics.
See lessWould alien life share DNA-like structures?
Whether alien life would share DNA-like structures depends on the fundamental principles of biochemistry and evolution in their respective environments. Here are some perspectives: 1. DNA as a Universal Blueprint? Argument for Similarity: DNA is an efficient, information-storing molecule, making itRead more
Whether alien life would share DNA-like structures depends on the fundamental principles of biochemistry and evolution in their respective environments. Here are some perspectives:
1. DNA as a Universal Blueprint?
Argument for Similarity:
DNA is an efficient, information-storing molecule, making it a likely candidate for life’s blueprint in other environments.
Its ability to replicate, mutate, and evolve underpins life’s complexity on Earth, suggesting that similar mechanisms might evolve elsewhere.
If alien life evolved in conditions similar to Earth (liquid water, carbon-based chemistry), DNA or a DNA-like molecule might emerge.
Argument for Differences:
DNA is not the only possible molecular system. Alien life might use entirely different chemical structures tailored to their environment.
For example, life in methane lakes (like on Titan) might rely on alternative molecules like PNA (Peptide Nucleic Acid) or entirely novel polymers.
2. Alternative Biochemistries
Silicon-Based Life: Silicon is a potential alternative to carbon, leading to biochemistries without DNA.
Ammonia or Methane Solvents: These could support life with molecular structures very different from DNA due to the unique properties of these solvents.
3. Shared Principles but Different Molecules
While DNA may not be universal, the principles of life—information storage, replication, and mutation—might be consistent. Aliens could have molecules performing similar functions, but with different building blocks (e.g., different sugars, bases, or backbones).
4. Convergent Evolution
If the laws of chemistry and physics lead to similar evolutionary pressures, convergent evolution might result in DNA-like molecules, even on distant worlds.
5. Panspermia Hypothesis
If life in the universe shares a common origin (e.g., spread via meteoroids), alien life may share DNA or similar structures.
While alien life might not use DNA specifically, they would likely rely on some form of molecule capable of storing and transmitting information. Whether it resembles DNA depends on the conditions and evolutionary pressures of their environment.
See less
Introduction: 10 most powerful bows In the modern world, we look to particle accelerators and nuclear payloads to define the limits of destructive power. But thousands of years ago, the thinkers of the Indian subcontinent conceptualized a terrifyingly advanced form ...

The Ken-Betwa Link Project (KBLP) is no longer just a blueprint on a map; it is a massive, active engineering reality that serves as the vanguard for India’s National Perspective Plan (NPP) for inter-basin water transfer. Aimed at ending the ...

Patriot vs Nationalist: Introduction The words patriot and nationalist are often used as if they mean the same thing. Both express a strong connection to one’s country, both evoke pride, and both can inspire people to act in the name ...

Introduction: The Eternal Hymn of Detachment and Devotion Shiv Rudrashtakam is one of the most profound Sanskrit hymns dedicated to Lord Shiva, the supreme yogi, destroyer of ignorance, and embodiment of pure consciousness. Composed by Adi Shankaracharya, this eight-verse stotra ...

A Prime-Adam Number is defined as a positive number that fulfills two conditions simultaneously: it is a prime number and also an Adam number. For example, take the number 13; its reverse is 31. The square of 13 is 169, and the ...

Introduction The 74th Miss Universe pageant, held on November 21, 2025, at the Impact Challenger Hall in Nonthaburi, Thailand, set a new benchmark in global beauty contests. Not merely a showcase of beauty and fashion, this year’s event stood as ...
Here’s an explanation for each statement: Some microorganisms can grow in environments with temperatures above the boiling point of water: This is correct. Certain microorganisms, known as thermophiles or hyperthermophiles, can thrive in extremely hot environments, such as hydrothermal vents, whereRead more
Here’s an explanation for each statement:
Thus, all three statements are correct. The correct answer is All three.
See less